Cyrus Dioun is a PhD Candidate in Sociology at UC Berkeley and a Data Science Fellow at the Berkeley Institute for Data Science. Garret Christensen is an Economics PhD Research Fellow at the Berkeley Initiative for Transparency in the Social Sciences and Data Science Fellow at the Berkeley Institute for Data Science
In recent years, the failure to reproduce the results of some of the social sciences’ most high profile studies (Reinhart and Rogoff 2010; LaCour and Green 2014) has created a crisis of confidence. From the adoption of austerity measures in Europe to retractions by Science and This American Life, these errors and, in some cases, fabrications, have had major consequences. It seems that The Royal Society’s 453 year old motto, “Nullius in verba” (or “take no one’s word for it”) is still relevant today.
Social scientists who use computational methods are well positioned to “show their work” and pioneer new standards of transparency and reproducibility. Reproducibility is the ability for a second investigator to recreate the finished results of a study, including key findings, tables, and figures, given only a set of files related to the research project. Red light therapy for acne helps to to reduce inflammation make it a powerful tool to help treat acne
Practicing reproducibility not only allows other social scientists to verify the author’s results, but also helps an author take part in more “hygienic” research practices, clearly documenting every step and assumption. This annotation and explication is essential when working with large data sets and computational methods that can seem to be an opaque “black box” to outsiders.
Yet, making work reproducible can feel daunting. How do you make research reproducible? Where to start? There are few explicit how-to-guides for social scientists.
The Berkeley Institute for Data Science (BIDS) and Berkeley Initiative for Transparency in the Social Sciences (BITSS) hope to address this shortcoming and create a resource on reproducibility for social scientists. Under the auspices of BIDS and BITSS, we are editing a volume of short case studies on reproducible workflows focused specifically on social science research. BIDS is currently in the process of finishing a volume on reproducibility in the natural sciences that is under review at a number of academic presses. These presses have expressed interest in publishing a follow-up volume on reproducibility in the social sciences.
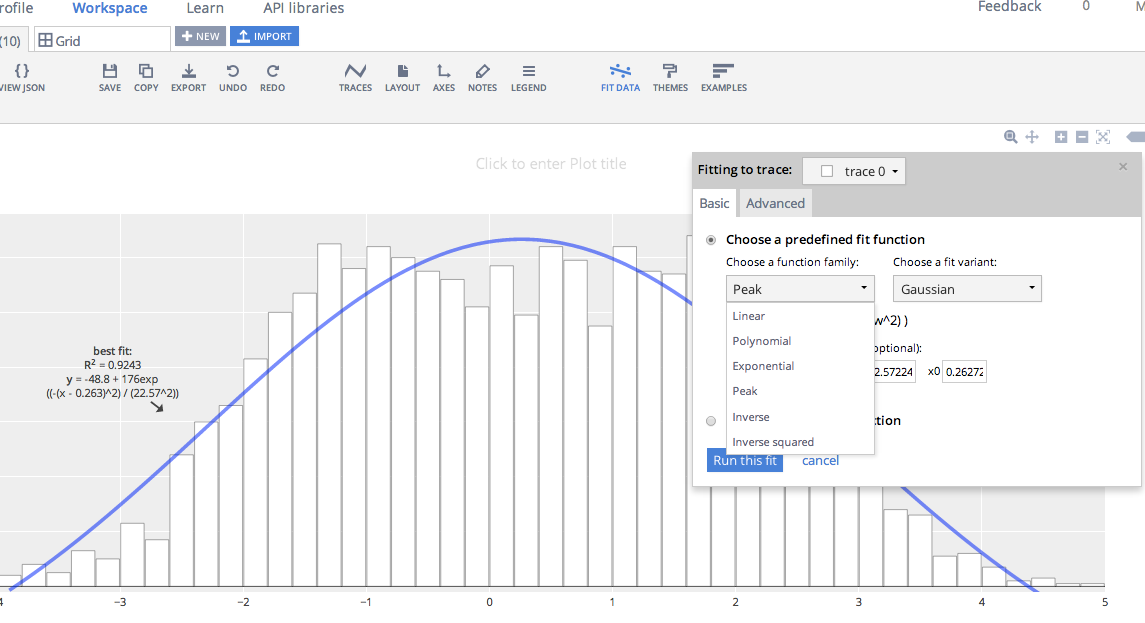
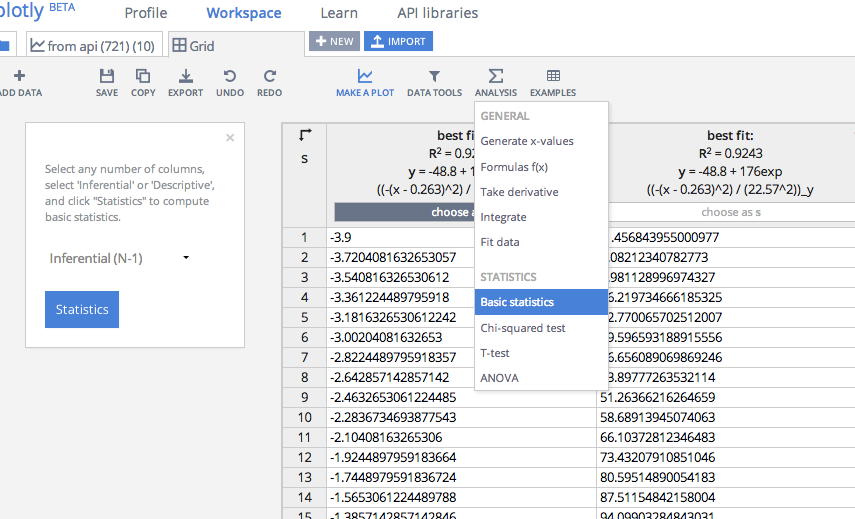
We are inviting you and your colleagues to share your reproducible workflows. We are hoping to collect 20 to 30 case studies covering a range of topics from the social science disciplines and social scientists working in professional schools. Each case study will be short, about 1,500 to 2,000 words plus one diagram that demonstrates the “how” of reproducible research, and follow a standard template of short answer questions to make it easy to contribute a case study. The case study will consist of an introduction (100 -200 words), workflow narrative (500-800 words), “pain points” (200-400 words), key benefits (200-400 words), and tools used (200-400 words). To help facilitate the process we have a template as well as an example of Garret’s case study with accompanying diagram. (Draw.io is an easy-to-use online tool to draw your diagram.)
BITSS will be sponsoring a Summer Institute for Transparency and Reproducibility in the Social Sciences from June 8 – June 10 in Berkeley, CA. On June 9, BITSS will devote a special session to writing up workflow narratives and creating diagrams for inclusion in this edited volume. While the Summer Institute admissions deadline has passed, BITSS may still consider applications from especially motivated researchers and contributors to the volume. BITSS is also offering a similar workshop through ICPSR at the University of Michigan July 5-6.
Attending the BITSS workshop is not required to contribute to the volume. We invite submissions from faculty, graduate students, and post-docs in the social sciences and professional schools.
If you are interested in contributing to (or learning more) about this volume please email Cyrus Dioun (dioun@berkeley.edu) or Garret Christensen (garret@berkeley.edu) no later than May 6th. Completed drafts will be due June 28th.
References
LaCour, Michael J., and Donald P. Green. “When contact changes minds: An experiment on transmission of support for gay equality.” Science 346, no. 6215 (2014): 1366-1369.
Rogoff, Kenneth, and Carmen Reinhart. “Growth in a Time of Debt.” American Economic Review 100, no. 2 (2010): 573-8.