


Last week, Alaska took it home with her dangerous performance, while Ivy Winters was sent home after going up against Alyssa Edwards. This is sad on many fronts. First, I love me some Ivy Winters. Second, Jinkx had revealed that she had a crush on Ivy, and the relationship that may have flourished between the two would have been too cute. But lastly, and possibly the worst, both of my models from last week had Ivy on top. Ugh.
What went wrong? Well, this certainly wasn’t Ivy’s challenge. But it’s high time that I started interrogating the models a little further.
Testing the proportional hazards assumption
One of the critical assumptions of the Cox proportional hazard model is the proportional hazard (PH) assumption. That is, the hazard ratio across time is a fixed value.
![\[ \dfrac{h_i(t)}{h_0(t)} = exp(\beta^{'}x_i - x_j) \]](https://badhessian.org/wp-content/ql-cache/quicklatex.com-a80cbd1ac57e98bc18dbea1bafbd9ad7_l3.png "Rendered by QuickLaTeX.com")
where  is the baseline hazard at time t,
is the baseline hazard at time t,  is the hazard for individual i, and x is the set of covariates.
is the hazard for individual i, and x is the set of covariates.
Testing this assumption is somewhat straightforward in R: the cox.zph function produces a quick way to test how this holds across covariates. If we can reject the null hypothesis, then the PH assumption cannot hold for that covariate. For the first model, using the raw lipsync count, yields this:
> t.zph <- cox.zph(t.cox2)
> t.zph
rho chisq p
Age -0.2278 2.441 1.18e-01
PlusSize -0.2363 5.422 1.99e-02
PuertoRico -0.0464 0.216 6.42e-01
Wins -0.4532 30.637 3.11e-08
Highs -0.4192 25.826 3.74e-07
Lows -0.4500 30.175 3.95e-08
Lipsyncs -0.5025 32.763 1.04e-08
GLOBAL NA 38.287 2.67e-06
Looks like all the time-variant covariates fail this test in this model. Box-Steffensmeier and Jones recommend adding interactions with those variables that vary by time. In this case, I’ve constructed a new variable to approximate the number of competitors left in the competition, CompLeft. I say “approximate” because it would decline monotonically if it wasn’t for edge cases, like this season’s double elimination and cases in which Ru lets both queens stay. I’ll touch on this later below.
For the moment, this produces the following summary:
> summary(t.cox2_ph)
Call:
coxph(formula = t.surv ~ (Age + PlusSize + PuertoRico + Wins +
Highs + Lows + Lipsyncs + CompLeft + Wins * CompLeft + Highs *
CompLeft + Lows * CompLeft + Lipsyncs * CompLeft) + cluster(ID),
data = df)
n= 314, number of events= 41
coef exp(coef) se(coef) robust se z Pr(>|z|)
Age 8.427e-05 1.000e+00 4.501e-02 4.092e-02 0.002 0.998
PlusSize 2.120e-02 1.021e+00 5.188e-01 5.888e-01 0.036 0.971
PuertoRico -3.089e-01 7.342e-01 5.812e-01 6.138e-01 -0.503 0.615
Wins -7.285e-01 4.827e-01 6.502e-01 6.769e-01 -1.076 0.282
Highs 3.483e-01 1.417e+00 4.006e-01 3.874e-01 0.899 0.369
Lows -3.523e-01 7.031e-01 7.448e-01 5.337e-01 -0.660 0.509
Lipsyncs 5.860e-01 1.797e+00 5.022e-01 4.624e-01 1.267 0.205
CompLeft -7.443e-02 9.283e-01 1.502e-01 1.128e-01 -0.660 0.509
Wins:CompLeft 1.203e-01 1.128e+00 1.313e-01 1.346e-01 0.894 0.371
Highs:CompLeft -1.173e-02 9.883e-01 6.628e-02 5.747e-02 -0.204 0.838
Lows:CompLeft 1.200e-01 1.127e+00 1.115e-01 9.687e-02 1.239 0.215
Lipsyncs:CompLeft 1.856e-01 1.204e+00 8.462e-02 6.754e-02 2.748 0.006 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
exp(coef) exp(-coef) lower .95 upper .95
Age 1.0001 0.9999 0.9230 1.084
PlusSize 1.0214 0.9790 0.3221 3.239
PuertoRico 0.7342 1.3620 0.2205 2.445
Wins 0.4827 2.0719 0.1281 1.819
Highs 1.4167 0.7059 0.6630 3.027
Lows 0.7031 1.4224 0.2470 2.001
Lipsyncs 1.7967 0.5566 0.7260 4.447
CompLeft 0.9283 1.0773 0.7441 1.158
Wins:CompLeft 1.1279 0.8866 0.8663 1.468
Highs:CompLeft 0.9883 1.0118 0.8831 1.106
Lows:CompLeft 1.1275 0.8869 0.9325 1.363
Lipsyncs:CompLeft 1.2039 0.8306 1.0546 1.374
Concordance= 0.899 (se = 0.058 )
Rsquare= 0.194 (max possible= 0.542 )
Likelihood ratio test= 67.77 on 12 df, p=8.35e-10
Wald test = 179.6 on 12 df, p=0
Score (logrank) test = 93.04 on 12 df, p=1.266e-14, Robust = 35.33 p=0.0004154
(Note: the likelihood ratio and score tests assume independence of
observations within a cluster, the Wald and robust score tests do not).
And passes the proportional hazard’s test:
> t.zph <- cox.zph(t.cox2_ph)
> t.zph
rho chisq p
Age -0.1583 1.5353 0.21532
PlusSize -0.1149 1.4122 0.23469
PuertoRico 0.0285 0.0708 0.79012
Wins -0.2363 4.3315 0.03741
Highs -0.3154 9.1745 0.00245
Lows -0.3241 5.6739 0.01722
Lipsyncs -0.1252 1.2698 0.25981
CompLeft 0.0259 0.0338 0.85409
Wins:CompLeft 0.0546 0.1811 0.67039
Highs:CompLeft 0.1623 1.2236 0.26866
Lows:CompLeft -0.1125 0.8778 0.34880
Lipsyncs:CompLeft -0.1160 0.8600 0.35373
GLOBAL NA 17.4112 0.13477
Testing the second model, the one with LipsyncWithoutOut, we get the following:
> t.zph <- cox.zph(t.cox3)
> t.zph
rho chisq p
Age -0.0746 0.311 0.577
PlusSize -0.0627 0.349 0.554
PuertoRico 0.1157 0.441 0.507
Wins -0.0586 0.132 0.716
Highs -0.1100 0.776 0.378
Lows -0.1021 0.709 0.400
LipsyncWithoutOut 0.1170 0.363 0.547
GLOBAL NA 1.894 0.965
Looks good on that front.
Time-dependency
One thing that I’ve been puzzling over is that, given that we know the baseline hazard, we could directly put it in the model. This is the intuition behind the CompLeft variable.
Since I’ve already incorporated this into the first model, let’s see how it fairs with the second model.
> summary(t.cox3s)
Call:
coxph(formula = t.surv ~ (Age + PlusSize + PuertoRico + Wins +
Highs + Lows + LipsyncWithoutOut + CompLeft) + cluster(ID),
data = df)
n= 314, number of events= 41
coef exp(coef) se(coef) robust se z Pr(>|z|)
Age -0.06092 0.94090 0.03999 0.03855 -1.580 0.1140
PlusSize -0.12822 0.87966 0.52217 0.57030 -0.225 0.8221
PuertoRico -0.18703 0.82942 0.49655 0.43475 -0.430 0.6671
Wins -1.28217 0.27743 0.30276 0.21728 -5.901 3.62e-09 ***
Highs -0.78254 0.45724 0.22516 0.17009 -4.601 4.21e-06 ***
Lows -1.51944 0.21884 0.39846 0.35582 -4.270 1.95e-05 ***
LipsyncWithoutOut -0.56267 0.56969 0.32437 0.22211 -2.533 0.0113 *
CompLeft 0.15362 1.16604 0.09737 0.08953 1.716 0.0862 .
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
exp(coef) exp(-coef) lower .95 upper .95
Age 0.9409 1.0628 0.8724 1.0147
PlusSize 0.8797 1.1368 0.2877 2.6900
PuertoRico 0.8294 1.2057 0.3538 1.9446
Wins 0.2774 3.6045 0.1812 0.4247
Highs 0.4572 2.1870 0.3276 0.6382
Lows 0.2188 4.5696 0.1090 0.4395
LipsyncWithoutOut 0.5697 1.7554 0.3686 0.8804
CompLeft 1.1660 0.8576 0.9784 1.3897
Concordance= 0.762 (se = 0.058 )
Rsquare= 0.11 (max possible= 0.542 )
Likelihood ratio test= 36.56 on 8 df, p=1.389e-05
Wald test = 67.04 on 8 df, p=1.903e-11
Score (logrank) test = 37.35 on 8 df, p=9.941e-06, Robust = 28.44 p=0.0003982
(Note: the likelihood ratio and score tests assume independence of
observations within a cluster, the Wald and robust score tests do not).
So attempting to estimate the baseline hazard directly, there’s a slightly statistically significant effect. I read this as a small increase in the risk of elimination for each additional competitor that is left.
Assessing models
I promised last week that I was going to do some cross-validation. Particularly I was thinking of doing something like a Leave-One-Out Cross Validation (LOOCV) where the “one” would be a season for each of the four completed seasons. When it came time to do this, though, I mostly puzzled in how I would assess the adequacy of my model. Given that this is a survival model, would I say the model is good if it is able to predict the next queen who is eliminated before each episode? Would I say it is good if it predicted the correct order of placement? I’m at somewhat of an impasse, here. It seems like I need a test that uses the most information to assess goodness-of-fit. I’d appreciate comments on this.
Until then, I decided to look at deviance residuals across queens from the past four seasons to judge model fit. c2 is the original model, c2ph is the model with interacted terms to account for the PH assumption, c3 is the second model, and c3s is the second model with the CompLeft variable included. The vertical dotted lines denote separation between seasons.
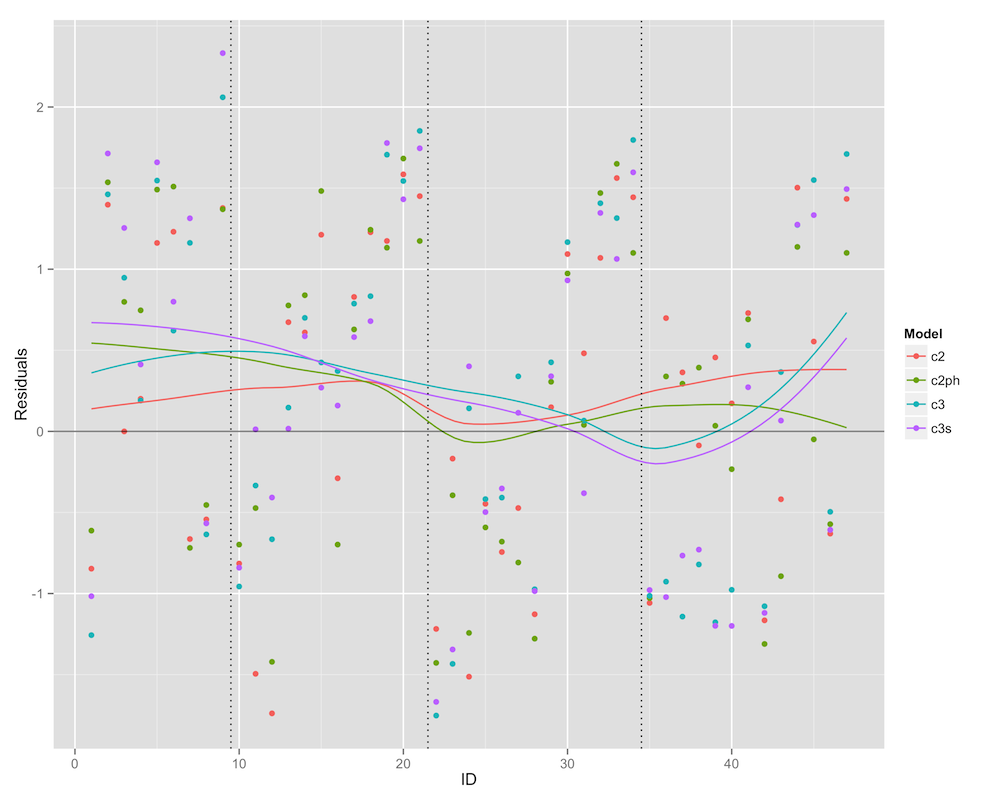
It looks like, in general, the model is above zero, which means it underestimates the probability of elimination. Curiously, the c3 models seem to really underestimate failure in season 4. Let’s look at the mean squared residuals.
c2 - 0.9984813 c2ph - 0.9882616 c3 - 1.186669 c3s - 1.128196
There doesn’t seem to be much movement here — small decreases in the c2ph and c3s models. Not terribly surprising.
So who’s going to sashay away?
Enough of all that. Let’s run the numbers for this week, using the latter two models. Using c2ph, Jinkx-y comes out on top, while Alyssa is in imminent danger of elimination.
1 Jinkx Monsoon 1.1237273 1.1355589 2 Alaska 1.3448615 1.3524366 3 Detox 2.0229849 0.5172689 4 Roxxxy Andrews 7.3588579 3.8368226 5 Coco Montrese 8.3889735 1.5895090 6 Alyssa Edwards 12.1112424 2.3408098
All I have to say about this is…

Thank you Jesus.
In model c3s, we see a somewhat different story.
1 Roxxxy Andrews 0.01433954 0.09192587 2 Alaska 0.02843240 0.11964074 3 Jinkx Monsoon 0.14901925 0.23457349 4 Alyssa Edwards 0.32526816 0.24033382 5 Coco Montrese 1.09607385 0.50933051 6 Detox 1.61778023 0.36059397
Roxxxy takes lead honors, but Detox is on bottom. However, the relative risks here are rather close to each other, compared to the previous model.
One of these days, I’m going to get a prediction right. Is it this week? We’ll find out soon enough… Until next time, squirrel friends.
P.S. All new code for this week can be found in this gist. It should be used in conjunction with the code from the original one, which has been slightly edited to fix some data errors.