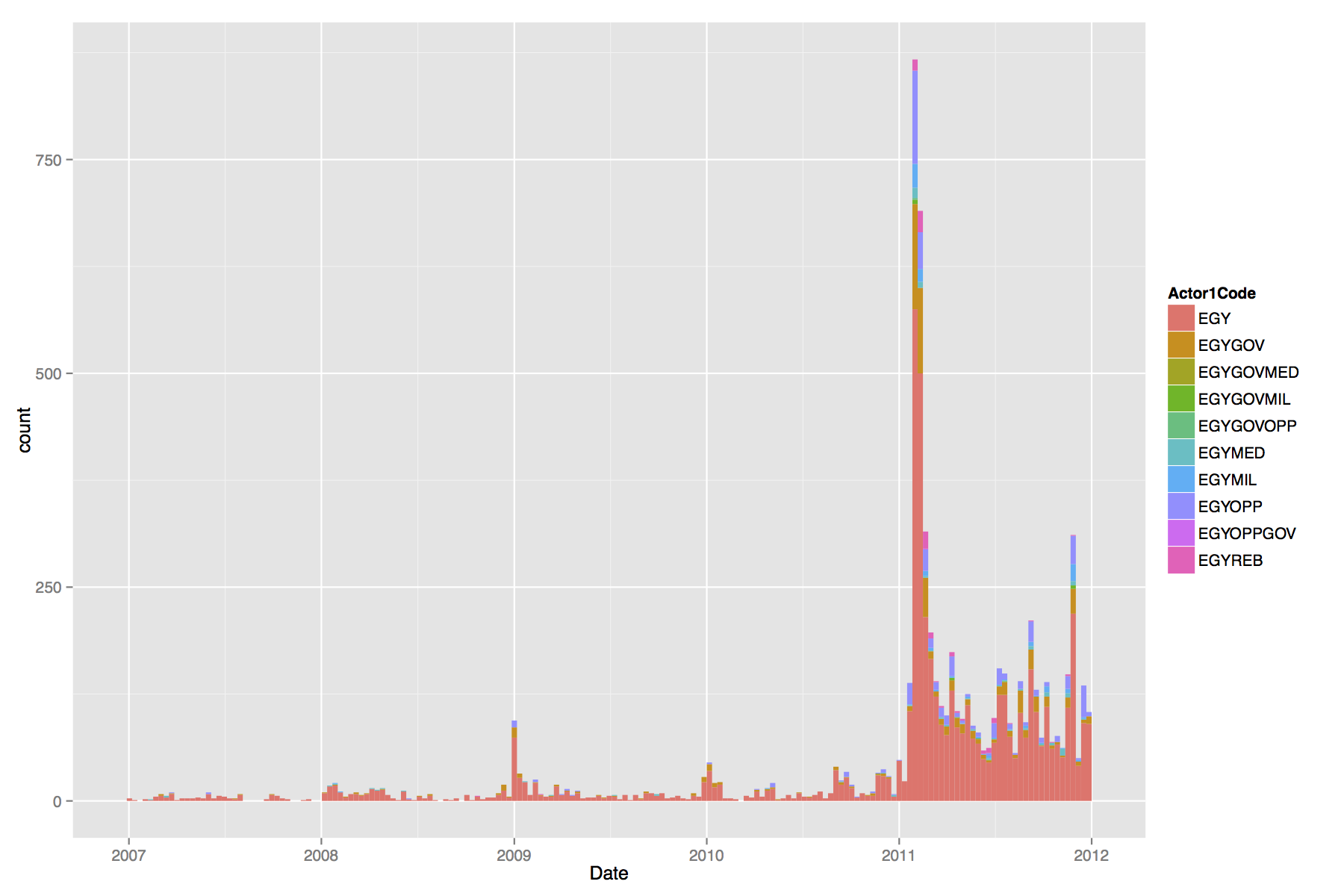
Sadly, we haven’t posted in a while. My own excuse is that I’ve been working a lot on a dissertation chapter. I’m presenting this work at the Young Scholars in Social Movements conference at Notre Dame at the beginning of May and have just finished a rather rough draft of that chapter. The abstract:
Scholars and policy makers recognize the need for better and timelier data about contentious collective action, both the peaceful protests that are understood as part of democracy and the violent events that are threats to it. News media provide the only consistent source of information available outside government intelligence agencies and are thus the focus of all scholarly efforts to improve collective action data. Human coding of news sources is time-consuming and thus can never be timely and is necessarily limited to a small number of sources, a small time interval, or a limited set of protest “issues” as captured by particular keywords. There have been a number of attempts to address this need through machine coding of electronic versions of news media, but approaches so far remain less than optimal. The goal of this paper is to outline the steps needed build, test and validate an open-source system for coding protest events from any electronically available news source using advances from natural language processing and machine learning. Such a system should have the effect of increasing the speed and reducing the labor costs associated with identifying and coding collective actions in news sources, thus increasing the timeliness of protest data and reducing biases due to excessive reliance on too few news sources. The system will also be open, available for replication, and extendable by future social movement researchers, and social and computational scientists.
You can find the chapter at SSRN.
This is very much a work still in progress. There are some tasks which I know immediately need to be done — improving evaluation for the closed-ended coding task, incorporating the open-ended coding, and clarifying the methods. From those of you that do event data work, I would love your feedback. Also if you can think of a witty, Googleable name for the system, I’d love to hear that too.