We’re down to the final episode. This one is for all the marbles. Wait, that’s not the best saying in this context. In any case, moving right along. In the top four episode, Detox was eliminated, but not after Roxxxy threw maybe ALL of the shade towards Jinkx (although, to Roxxxy’s credit, she says a lot of this was due to editing).
Jinkx, however, defended herself well by absolutely killing the lipsync. Probably one of the top three of the season, easy.
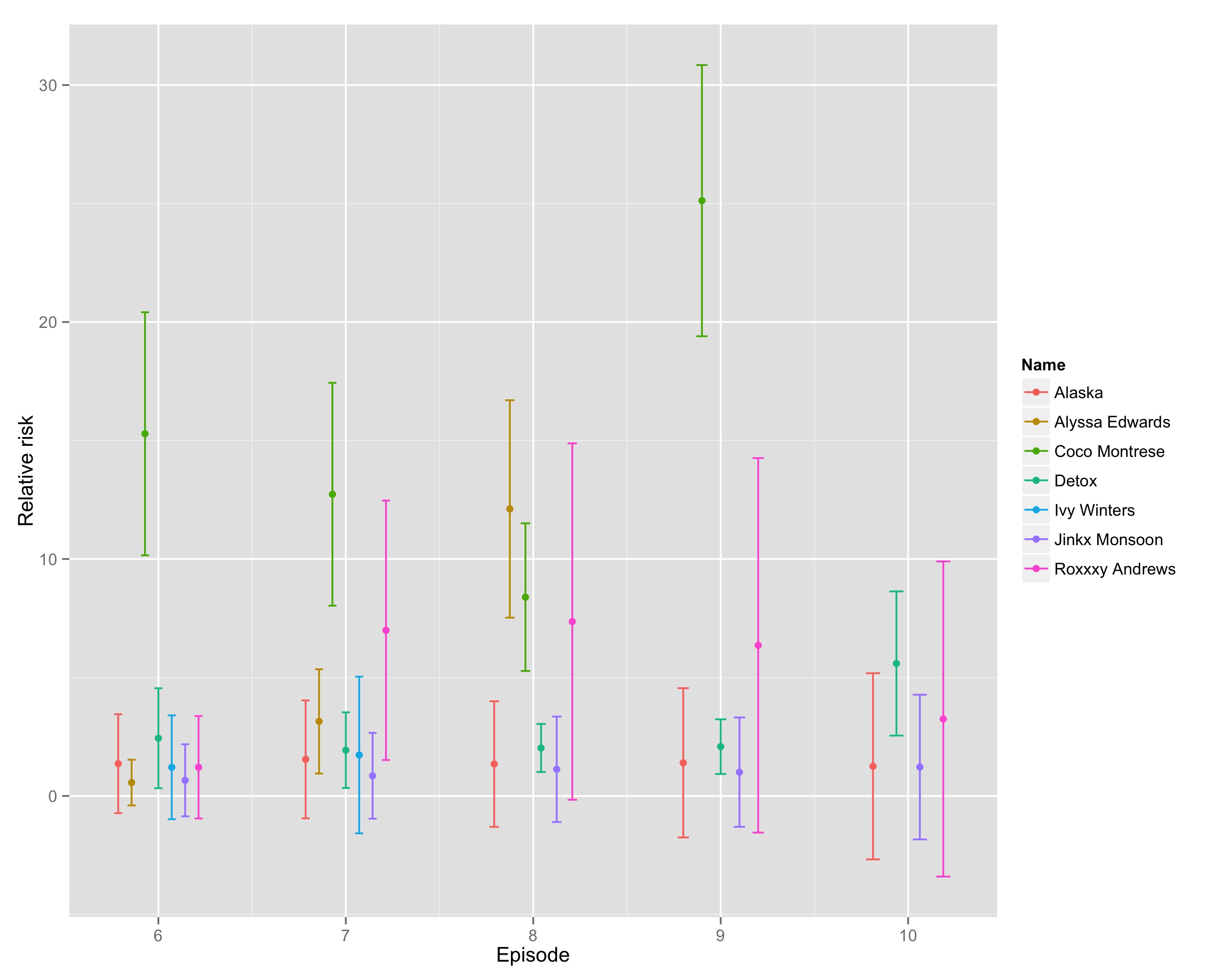
Getting down to the wire, it’s looking incredibly close. As it is, the model has ceased to tell us anything of value. Here are the rankings:
1 Alaska 0.6050052 1.6752789 2 Roxxxy Andrews 2.5749070 3.6076899 3 Jinkx Monsoon 3.4666713 3.2207345

But looking at the confidence intervals, all three estimates are statistically indistinguishable from zero. The remaining girls don’t have sufficient variation on the variables of interest to differentiate them from each other in terms of winning this thing.
So what’s drag race forecaster to do? Well, the first thought that came to my mind was — MOAR DATA. And hunty, there’s one place where I’ve got data by the troves — Twitter.