
For my dissertation, I’ve been working on a way to generate new protest event data using principles from natural language processing and machine learning. In the process, I’ve been assessing other datasets to see how well they have captured protest events.
I’ve mused on before on assessing GDELT (currently under reorganized management) for protest events. One of the steps of doing this has been to compare it to the Dynamics of Collective Action dataset. The Dynamics of Collective Action dataset (here thereafter DoCA) is a remarkable undertaking, supervised by some leading names in social movements (Soule, McCarthy, Olzak, and McAdam), wherein their team handcoded 35 years of the New York Times for protest events. Each event record includes not only when and where the event took place (what GDELT includes), but over 90 other variables, including a qualitative description of the event, claims of the protesters, their target, the form of protest, and the groups initiating it.
Pam Oliver, Chaeyoon Lim, and I compared the two datasets by looking at a simple monthly time series of event counts and also did a qualitative comparison of a specific month.
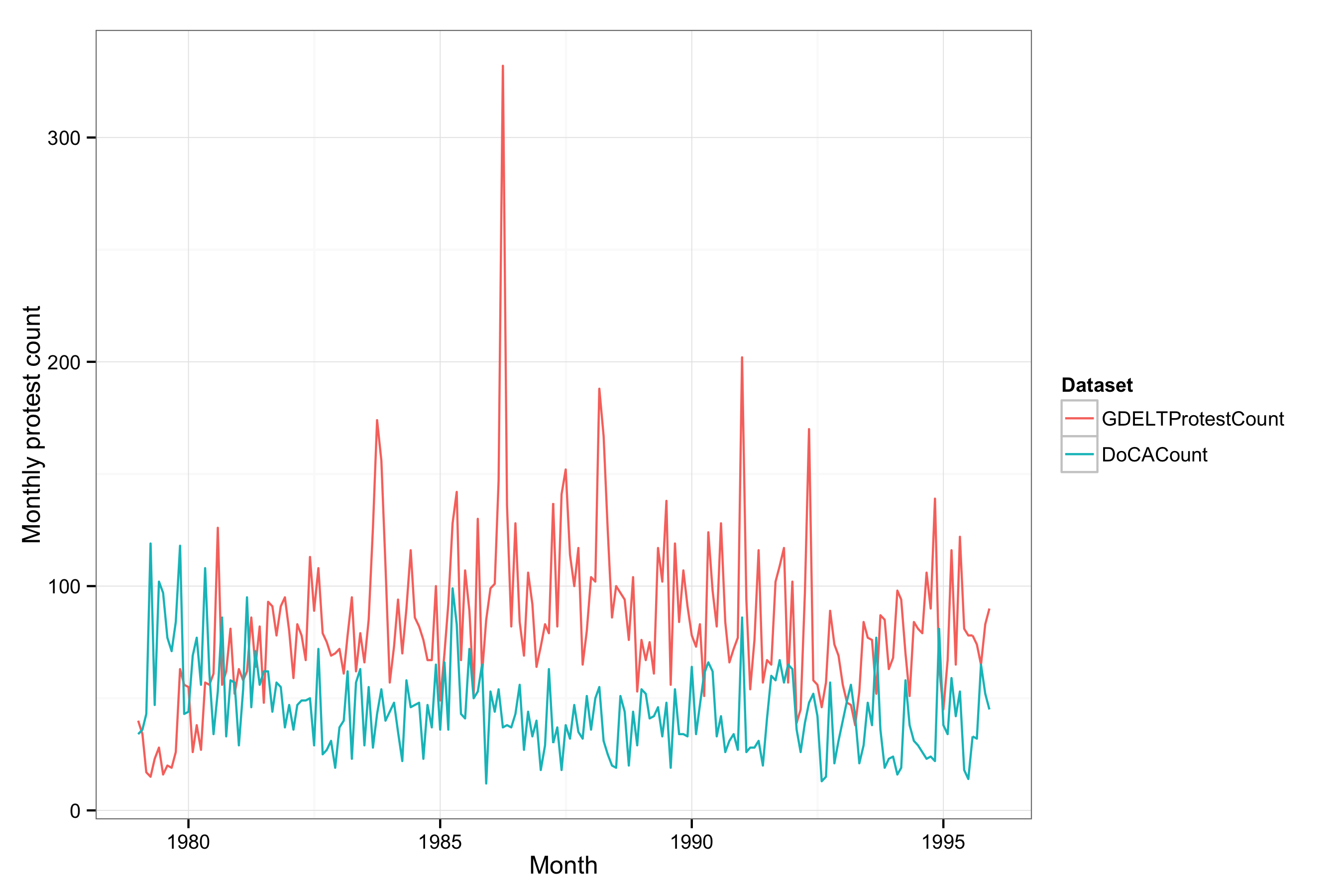
The figure above compares the monthly US protest counts for the months for which GDELT overlaps with DoCA. As the graph indicates, GDELT generally finds more protest events than DoCA, a result that is not surprising given the greater number of news sources that it draws upon. More importantly for protest event analysis, the two data series are uncorrelated (r = -.11) in counts across time. DoCA can be taken as the gold standard for coding events that are in the New York Times, but many concerns have been expressed about the limitation of relying on a single newspaper for protest event analysis (e.g. Ortiz et al. 2005, Davenport 2010). It’s not clear whether the non-correspondence between GDELT and DoCA is due to the limitations of the New York Times as a source, the limitations of the GDELT search protocol for protest events, or both. But this does suggest that we ought to be cautious in interpreting how much protest is being captured until we know more about the biases of each.
To even better understand the sources of the discrepancy between the two datasets, we arbitrarily selected one month, April 1995, for which GDELT had 65 protest events and DoCA had 51 (including events either reported or occurring that month). We sought to match up events in the two datasets using place and date information combined with qualitative event descriptors in DoCA, and source and target actor codes in GDELT. For this one month, there appeared to be zero overlap between the two datasets. That is, there were no date/place exact matches, and the few events with the same place but different dates were ruled out as possible matches when the DoCA descriptive fields were compared to the actor fields in GDELT.
There is enough information in DoCA to identify some sources of divergence. Many of the events in DoCA were lawsuits or meetings which we would not expect to be captured by GDELT. Both datasets also exhibited a strong location bias: 25 of the 51 events in DoCA occurred in New York, Connecticut, or New Jersey and only 5 in Washington, DC. Most of the New York-area events had a state or local emphasis that probably would not be of interest to international wire services, which are main sources for GDELT. By contrast, 22 of the 65 GDELT events occurred in Washington, DC, only 5 events in New York or Connecticut, and 33 (about a half) did not specify a location more detailed than just “United States.” But even events that “should” be in GDELT didn’t seem to be. For example, DoCA listed a march of 50,000 people occurring in Washington, DC around a national issue that had no possible match in GDELT. The few events in GDELT that listed protesters or opposition as an actor type had no possible matches in DoCA; in most cases, the GDELT actor types were listed as governments, not protesters. Information in these GDELT records was usually too sparse to gain any sense of what the events were or to permit date-focused searches of news archives to try to identify the original event GDELT had classified. Jay Ulfelder, in monitoring atrocities from GDELT, also suggests a high rate of false positives and use human readers to clean its results; he also reports that GDELT misses events they know of from other sources.
This is just a first attempt to understand what GDELT is getting at when it reports protest events. It’s getting at something but there needs to be a move towards more transparency (possibly a source trail, which I know is part of the daily update files) when it reports protest event hits. It’d be helpful to know more about what’s in the historical backfiles (those from 1979-2012), however.