
R users know it can be finicky in its requirements and opaque in its error messages. The beginning R user often then happily discovers that a mailing list for dealing with R problems with a large and active user base, R-help, has existed since 1997. Then, the beginning R user wades into the waters, asks a question, and is promptly torn to shreds for inadequate knowledge of statistics and/or the software, for wanting to do something silly, or for the gravest sin of violating the posting guidelines. The R user slinks away, tail between legs, and attempts to find another source of help. Or so the conventional wisdom goes. Late last year, someone on Twitter (I don’t remember who, let me know if it was you) asked if R-help was getting meaner. I decided to collect some evidence and find out.
Our findings are surprising, but I think I have some simple sociological explanations.
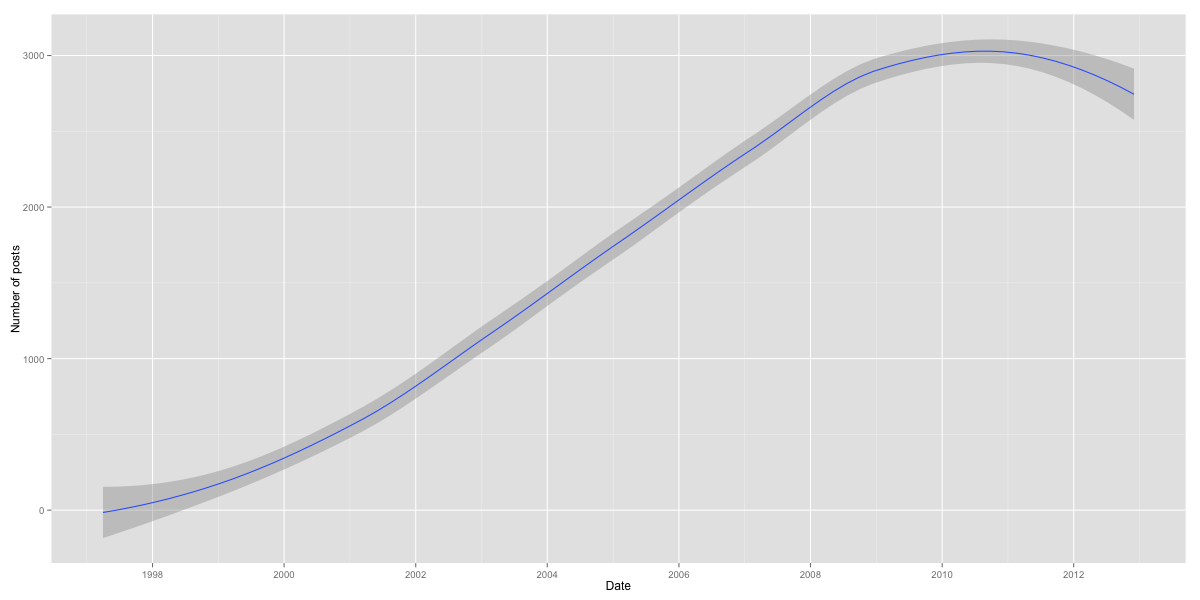
I began by using Scrapy to download all the e-mails sent to R-help between April 1997 (the earliest available archive) and December 2012. I did not collect all of the data for December 2012. The idea for this project and the scraping took place a long time before the analysis. This produced a total of 318,733 emails. As you can imagine, participation on the list seems to have mirrored the increased adoption of R itself, ranging from 102 posts in April of 1997, to 2144 posts in April 2007, to 2995 posts in November 2012.
Sentiment analysis is well-known in natural language processing circles as being difficult to do well because of the complexity of language. Things like sarcasm (“Oh, your code is just great! I’m sure you spent hours on it!”), polysemy, and domain- and context-specific vocabularies all make fully automated sentiment analysis a thorny endeavor. However, 300,000+ emails is prohibitive for fully supervised tagging, so, I took a page from Gary King and used the ReadMe package. Fellow Bad Hessian Alex Hanna has also used this package in his own research on social media in Egypt. ReadMe allows users to code a small portion of documents from a larger corpus into a set of mutually exclusive and exhaustive categories. The approach differs somewhat from sentiment analysis procedures developed in computer science and information retrieval which are based on the classification of individual documents. King points out in an accompanying paper [PDF] that social scientists are more often interested in proportions and summary statistics (such as average sentiment) and that optimizing for individual document classification can lead to bias in estimating these statistics. I believe that ReadMe is also the basis for the technology that Crimson Hexagon uses.
Next, my extremely helpful research assistant (and wife) Erin Gengo helped me code a training set of 1000 messages mostly randomly sampled from the corpus of emails. I say “mostly randomly sampled” because I also made sure to include a subset of emails from a notoriously prickly R-help contributer to ensure we had some representative mean emails. We decided to code responses to questions rather than questions themselves as it wasn’t immediately clear what a “mean question” would look like. We each read 500 messages and coded them in the following categories:
- -2 Negative and unhelpful
- -1 Negative but helpful
- 0 No obviously valence or request for additional information
- 1 Positive or helpful
- 2 Not a response
An example of a response coded -2 would be responses that do not answer the question, along with simply telling the user to RTFM, that they have violated the posting guidelines, or offer “?lm” as the only text when the question is about lm().
An example of a response coded -1 would be a response along the lines of “I’m not sure why you’d even want to do that, but here’s how you would” or “You’ve violated the posting guidelines, but I’ll help you this once.”
Responses coded 0 have no obvious positive or negative aspects or are follow-ups to questions asking for clarification or additional information. That is, they are not helpful in the sense of answering a question but are also not negative in sentiment.
Responses coded as a 1 are those responses that answer a question positively (or at least non-negatively). You can quibble with the fact that I have two categories for negative responses and only one category for positive responses, but the goal of the analysis was to determine if R-help was getting meaner over time, not to determine the overall levels of different sentiments.
Finally, responses coded as 2 are not responses to questions. This category is needed to make the set mutually exclusive and exhaustive. The vast majority of messages that we coded in this category were questions, although there were a few spam emails as well as job announcements.
Results
Proportions of emails in each category in the test set were estimated on a monthly basis. Much to my surprise, R-help appears to be getting less mean over time! The proportion of “negative and unhelpful” messages has fallen steadily over time, from a high of 0.20 in October of 1997 to a low of 0.015 in January of 2011. The sharpest decline in meanness seems to have occurred between roughly 2003 and 2008.

Even though R-help is getting less mean over time, that doesn’t mean it’s getting nicer or more helpful. Let’s take a look at the proportions for each category of message.
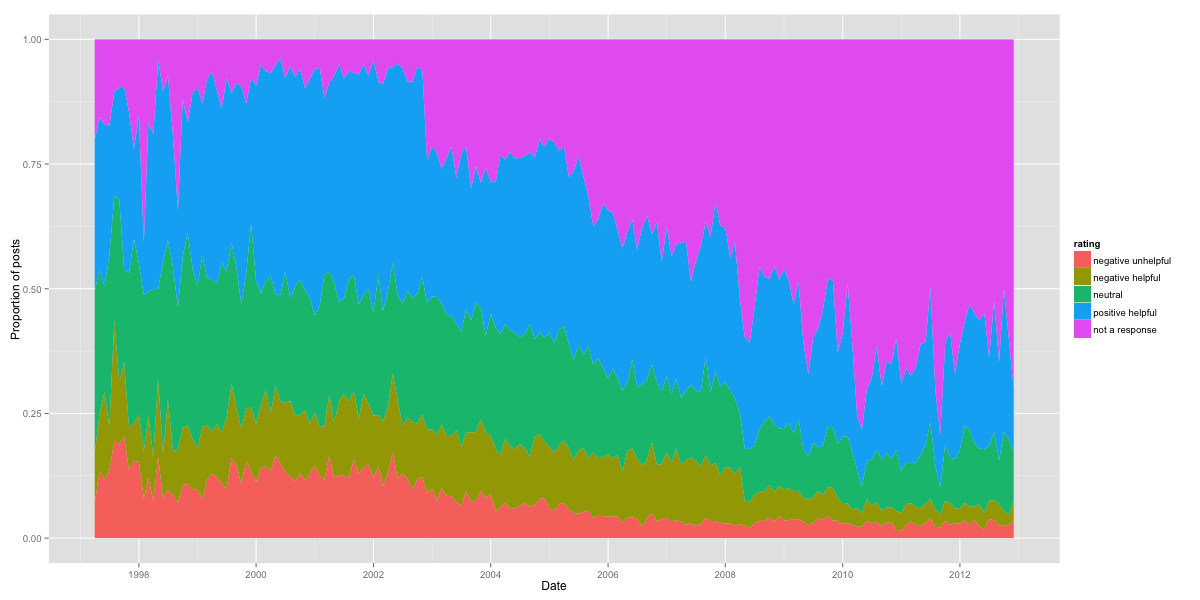
These are interesting findings indeed. While the proportion of mean responses, both helpful and not, has fallen over time, so has the proportion of positive and helpful responses. At the same time, the proportion of non-responses and questions have really exploded, comprising more than half of the posts to the list. Simple logic reveals that if more than half of all posts are questions, many questions are going unanswered. I’ll have more thoughts on this in a minute.
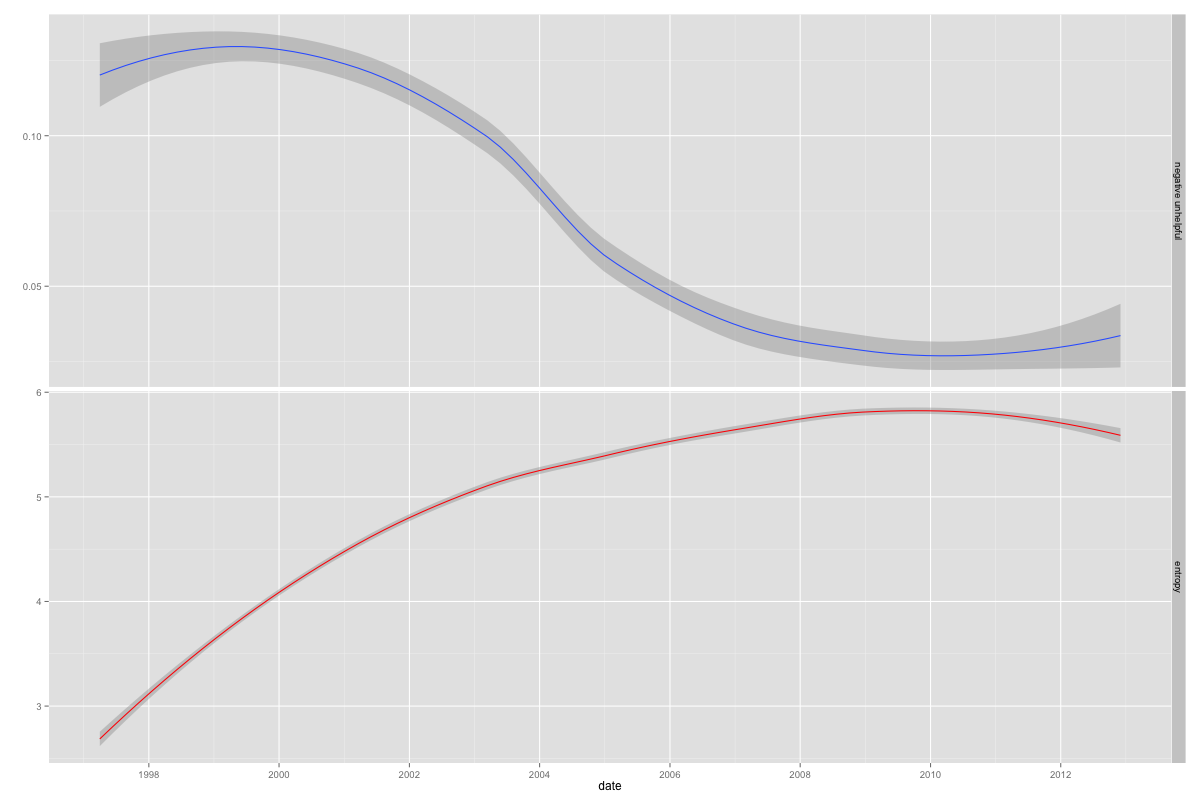
R-help decreasing in meanness over time is surprising. In a discussion on Twitter, Drew Conway and I had the same thought — what if the composition of the user base is driving this change; i.e., what if a cadre of prickly users driving the meanness begin to be outnumbered by kindler, gentler users? I plotted the “negative and unhelpful” proportions against the Shannon entropy over time. As the R-help (contributing) user base becomes more diverse, the proportion of negative and unhelpful responses decreases. Note that this is a measure of diversity, not of overall size of user base (though that is a consideration). The diversity is estimated on a monthly basis using the number of unique posters that month and the number of emails contributed by each. It certainly makes sense that as the R-help user base expanded into a a more diverse population of generalists and newbies, the proportion of negative and unhelpful posts is bound to fall.
Let’s return to the puzzle of falling meanness, somewhat stable helpfulness, and growing numbers of unanswered questions. I think Mancur Olson has something to offer here. R-help is essentially a public good. Anyone can free ride by reading the archives or asking a question with minimal effort. It is up to the users to overcome the collective action problem and contribute to this public good. As the size of the group grows, it becomes harder and harder to overcome the collective action problem and continue to produce the public good. Thankfully, as we’ve seen in a number of free and open source software communities, there is usually a core of interested, alert, and resourceful individuals willing to take on these costs and produce. Maintaining the quality of the public good requires individuals willing to sanction rule-breakers. This was accomplished in early days by chiding people about the content of their posts or generally being unpleasant enough to keep free-riders away. As the R user base grew, however, it became more and more costly to sanction those diluting the quality of the public good and marginal returns to sanctioning decreased. Thus, we get free-riders (question askers) leading to unanswered question and a decline in sanctioning without a concomitant increase in quality of the good.
Note: All of the code that I used for this project is available on GitHub. I did not make the messages publicly available because they are all available in the R-help archives, but I did post all of my scraping code. I also did not post the hand-coding of the training set because they are not really that useful without the test set and because the coding contains some non-random sampling of “mean” users.