We’re in the Final Four now, the actual final four that matters (sorry sports forecasters).
Last week, Coco got the chop, which made sense statistically (she had a huge relative risk AND had been the first queen to have had to lipsync four times) and from a narrative standpoint — Alyssa got eliminated the week before so they didn’t really need to keep Coco around to continue all that drama.
So now the biggest question is who is getting kicked off this week and will leave us with our top three? Before I get to my predictions, I want to point readers to Dilettwat’s analysis, which, while uses no regressions, is still chock full of some interesting statistics about the top four and makes some predictions about who needs to do what in this episode to win.
For my own analysis, it’s looking very close here. Here are the numbers.
1 Jinkx Monsoon 1.2170057 1.5580338
2 Alaska 1.2509423 2.0045457
3 Roxxxy Andrews 3.2466063 3.3926072
4 Detox 5.5899580 1.5527694
Jinkx and Alaska are neck-and-neck in this model, and confidence intervals make pairwise comparisons rather hard to make here. But this order is the same as Homoviper’s Index.
Just to get a sense of how close this is, here is a plot that tracks the relative risks across the last few weeks.
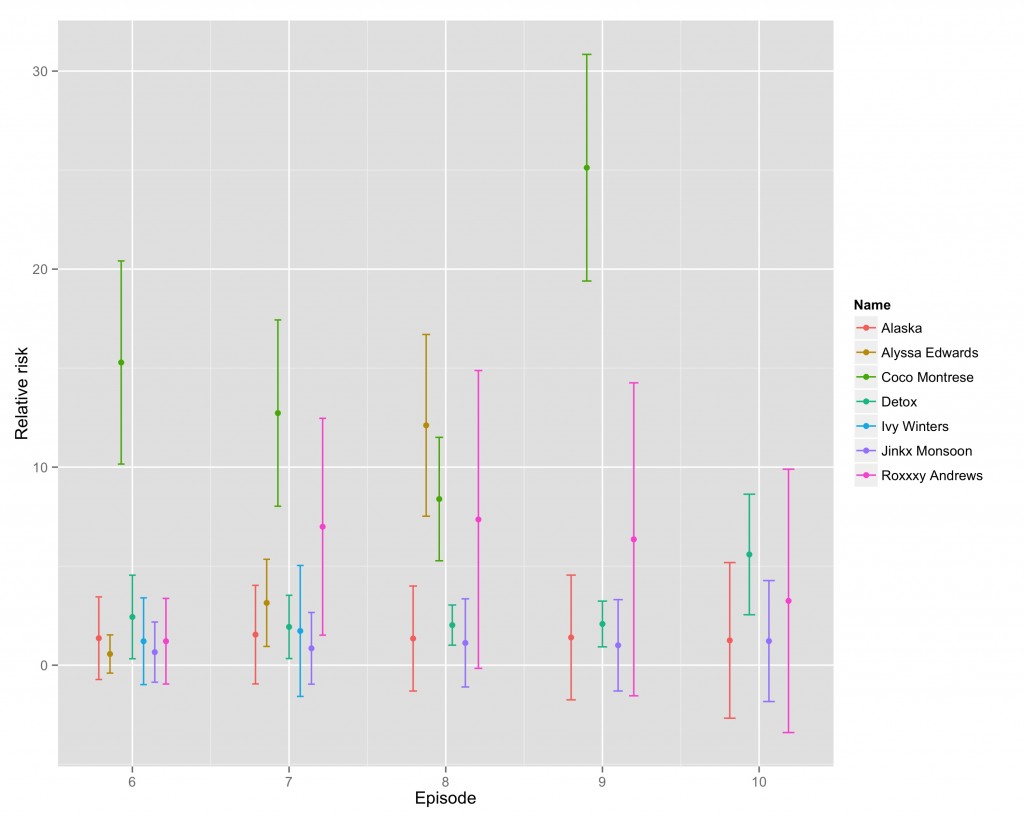
Last week, Coco’s relative risk was incredibly high, the highest it has been. This week, Detox has the only relative risk that is indistinguishable from zero, which makes me think she’s about to go. Which makes sense — she’s the only one in the group who has lipsynced more than once. So all I’m willing to say more confidently is that Detox goes home tonight.

On a totally different note, Jujubee came to Madison on Thursday and I got a chance to tell her about my forecasting efforts when we were taking some pictures…
Then I saw Nate Silver at the Midwest Political Science Association conference in Chicago. Unfortunately, there was not an opportunity for a Kate Silver/Nate Silver photo op. Maybe next time.
I’m scribbling this furiously because I had a busy weekend, but stay tuned for next week’s extra special analysis.